Introduction
Vous allez écrire à peu près la même application Web que dans le TP 1, un chat avec un LLM, mais en utilisant LangChain4j pour accéder à l'API du LLM (Gemini).
Dans le TP 1 vous avez écrit une application qui utilise directement les endpoints REST de l'API du LLM, avec des documents JSON explicitement construits dans l'application. LangChain4j permet de travailler à un plus haut niveau, sans s'occuper de la manipulation des documents JSON, qui est assez pénible.
LangChain4j
Le framework LangChain4j est actuellement un standard de facto pour l'utilisation des LLM en Java, et en particulier pour faire du RAG. Il permet un plus haut niveau d'abstraction.
LangChain4j est au départ une adaptation à Java de LangChain. LangChain est un framework open source qui ajoute une couche d'abstraction aux APIs des LLMs. Cette couche d'abstraction améliore la portabilité des applications (il est plus simple de changer de LLM) et facilite l'utilisation des APIs. LangChain4j permet d'enchainer aisément plusieurs interactions avec des LLMs, et des traitements complémentaires. Exemples de traitements complémentaires :
- Lecture de fichiers ou d'une base de données, qui contiennent des données ou des règles de procédures particulières à un domaine ou à une entreprise, pour les faire prendre en compte par les LLMs.
- Accès Internet pour vérifier une information donnée par un LLM.
Dépendance Maven à ajouter pour LangChain4j aux fichiers pom.xml de vos projets Java (choisissez le dernier numéro de version, à la place de 0.36.2 ; le numéro doit être le même pour toutes les dépendances) :
Attention, la version 0.36.0 contient un bug gênant pour les TPs. Utilisez la version 0.36.2 ou une version ultérieure.
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j</artifactId> <version>0.36.2</version> </dependency>
Dépendance Maven à ajouter en plus pour l'utilisation de l'API de Gemini avec LangChain4j :
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-core</artifactId> <version>0.36.2</version> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-google-ai-gemini</artifactId> <version>0.36.2</version> </dependency>
Remarque : (Pas pour ce TP)
Si vous voulez utiliser OpenAi, la dépendance Maven à ajouter en plus pour l'utilisation de l'API d'OpenAI avec LangChain4j :
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-open-ai</artifactId> <version>0.36.2</version> </dependency>
Ressources pour LangChain4j
- Get started : https://docs.langchain4j.dev/get-started
- Documentation en général : https://docs.langchain4j.dev/
- Javadoc : https://docs.langchain4j.dev/apidocs/index.html, https://langchain4j.github.io/langchain4j/apidocs/index.html
- Tutoriel : https://docs.langchain4j.dev/category/tutorials, https://langchain4j.github.io/langchain4j/tutorials/
- Exemples de base : https://github.com/langchain4j/langchain4j-examples, https://github.com/langchain4j/langchain4j-examples/tree/main/other-examples/src/main/java
- Liste des noms des modèles dans l'API de Gemini : https://generativelanguage.googleapis.com/v1beta/models?key=AIzuuyDTjkuPHjBY... (collez ici votre clé Gemini).
- Problèmes : https://github.com/langchain4j/langchain4j/issues
Description de l'application
Vous aller refaire l'application Web du TP1 en utilisant LangChain4j. La seul différence est que vous n'aurez pas le mode "debug" qui affichait le JSON échangé entre le client de l'API et l'API (ce JSON dépend du LLM utilisé) :
Voici à quoi va ressembler l'interface utilisateur de votre application après 3 échanges avec le LLM (affichés dans la zone de droite) :
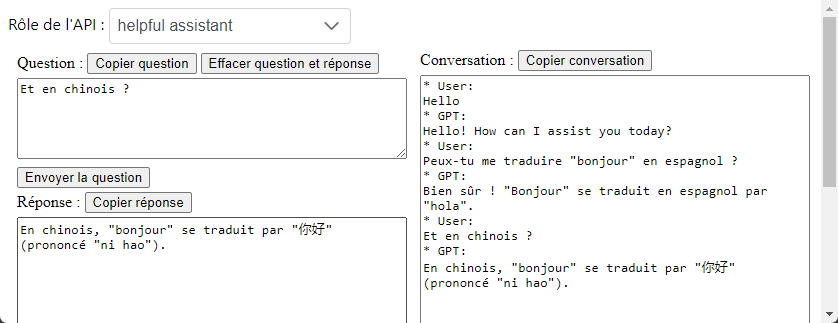
Cette page aura un backing bean. Ce backing bean utilisera un bean CDI (une classe gérée par CDI pour les injections de dépendance) qui utilisera LangChain4j pour envoyer des requêtes à l'API d'OpenAI.
Quelques tests avec LangChain4j
Avant de vous lancer dans le projet d'application Web décrit ci-dessus, vous allez commencer par vous familiariser avec LangChain4j en écrivant quelques programmes courts qui utilisent les classes de base de LangChain4j.
Ces programmes seront lancés avec une méthode main d'une classe Java ordinaire. Vous écrirez une classe par test ; chaque classe aura une méthode main. Pour chaque test, vous lancerez l'exécution de la classe de test. A la fin vous aurez donc autant de classes que de tests dans votre projet.
Comme pour tous les projets de ce cours, créez un reporitory GitHub pour ce projet. Faites au moins un commit par test, suivi d'un push vers GitHub. N'oubliez pas d'insérer votre nom dans le projet et dans vos noms de package.
Pour ces tests, créez un projet Java ordinaire (pas un projet Web Jakarta EE comme pour les TPs 0 et 1) qui utilise Maven.
Aidez-vous du support de cours sur LangChain4j et de la javadoc pour écrire ces tests.
Test 1 : pour se chauffer...
Vous allez utiliser la classe GoogleAiGeminiChatModel qui implémente l'interface ChatLangageModel. Une instance de cette classe est créée avec le pattern "builder". Le nom du modèle est gemini-1.5-flash. Donnez une température de 0,7 (vous pourrez aussi tester d'autres valeurs pour voir).
Le code de la classe pose une question simple et affiche la réponse de l'API du LLM.
Consultez le cours pour voir comment faire.
Correction
Test 2 : un traducteur
Comme le test 1 mais vous allez ajouter l'utilisation des classes PromptTemplate et Prompt.
Utilisez le PromptTemplate qui pourrait convenir pour un traducteur, avec une variable pour le texte à traduire. Le prompt pourrait, par exemple, correspondre à "Traduis le texte suivant en anglais : ****" avec la valeur de "****" donnée par un paramètre du template.
Correction
Test 3 : embeddings
Le programme utilise un modèle d'embeddings pour générer 2 embeddings de 2 phrases et ensuite calculer leur similarité par la métrique du cosinus.
Une des difficultés est de trouver le bon nom de modèle pour les embeddings. La liste des noms de modèles pour Gemini peut être obtenue en tapant cet URL dans un navigateur :
https://generativelanguage.googleapis.com/v1beta/models?key=AIzuuyDTjkuPHjBY... (collez ici votre clé Gemini). Attention, le nom du modèle à mettre dans le code est le nom qui est après "models/" dans la liste des modèles.
Ensuite, allez voir l'interface EmbeddingModel et la classe GoogleAiEmbeddingModel dans la javadoc de LangChain4j. Au moment où ces lignes sont écrites, il n'y a pas de builder pour créer une instance de GoogleAiEmbeddingModel. Utilisez le constructeur qui prend de nombreux paramètres. Pour le type de tâche, choisissez TaskType.SEMANTIC_SIMILARITY puiqu'on veut calculer une similarité. Pour la dimension des vecteurs d'embeddings, choisissez par exemple 300. Pour la durée du timeout, allez voir dans la javadoc du JDK.
Donnez plusieurs couples de phrases, similaires ou pas, pour voir la similarité (plus elle est proche de 1, meilleur elle est).
Pour récupérer les embeddings à partir des réponses du modèle d'embeddings, utilisez la méthode content().
Pour calculer la similarité, utilisez la classe CosineSimilarity (cherchez dans la javadoc).
Correction
Test 4 : pour vous donner envie de voir la suite du cours ;-)
Introduction
Tout d'abord, reprenez le test 1 et posez la question "Comment s'appelle le chat de Pierre ?". Voyez la réponse du LLM.
Maintenant, ajoutez un fichier texte "infos.txt" à la racine de votre projet Java. Voici son contenu :
Le nom du chien de Jacques est Médor. Le nom du chat de Pierre est Felix. La capitale de la France est Paris.
Créez une nouvelle classe de test.
Pour ce test le code vous est donné, mais essayez de le comprendre.
Vous devez ajouter une dépendance dans pom.xml. Le code utilise un service IA avec une interface Java Assistant implémentée par LangChain4j, qui est utilisée pour un chat avec le LLM (toute la "magie" de l'implémentation est effectuée par la classe AiServices). Vous pouvez choisir le nom de la méthode de l'interface.
Exécutez la méthode main de la classe. Alors ? Vous venez d'utiliser le RAG (Retrieval-Augmented Generation) : des informations ont été fournies au LLM pour qu'il génère de meilleures réponses à certaines questions. C'est comme cela que les entreprises peuvent fournir au LLM des informations récentes ou non publiques.
Remplacez la question du programme par celle-ci : "Pierre appelle son chat. Qu'est-ce qu'il pourrait dire ?". La réponse du LLM devrait mieux vous montrer que le LLM a utilisé ses capacités linguistiques acquises pendant son entrainement et les informations du fichier infos.txt pour répondre à votre question.
Que se passe-t-il si vous modifiez la dernière ligne en disant que Marseille est la capitale de la France et que vous demandez la capitale de la France au LLM ? Sans configuration particulière, les informations récupérées par le RAG l'emportent sur les connaissances acquises pendant l'entrainement de base (le LLM a certainement appris pendant l'entrainement que la capitale de la France est Paris).
Plus fort
Bon, ce que fait le programme n'est quand même pas extraordinaire. On va faire un peu plus fort : copiez le pdf du support de cours sur le machine learning à la racine du projet et posez une question dont la réponse est dans le support ; par exemple "Quel est l'objectif du cours 'Machine Learning' de Richard Grin ?". Vous pouvez même essayer de lui demander dans quel slide il a trouvé l'information. C'est déjà plus intéressant, non ? Posez 2 ou 3 questions supplémentaires pour voir comment réagit le LLM (par exemple de vous faire un quiz avec QCM sur le machine learning en utilisant le support de cours). Vous remarquerez sans doute que le LLM ne se contente pas de recopier le texte du support de cours ; il récrit la réponse à sa façon, souvent meilleure que le contenu du support ;-) (le support essaie d'être concis, sans souci de style).
Pour obtenir un bonus : Dans l'email pour signaler que vous avez fini cette partie du TP, en plus de l'URL du dépôt GitHub de votre projet, écrivez une des questions que vous avez posée et la réponse du LLM.
Rappelez-vous que le LLM peut parfois se tromper, broder et même inventer des informations, c'est son péché mignon. C'est pour cela qu'il faut parfois lui mettre des garde-fous ou lui fournir des informations supplémentaires en affinant la recherche d'informations par RAG. Mais attention, le RAG n'est pas infaillible ; le LLM peut encore ne pas donner la bonne information, avec le bonne façon de le dire. C'est pour cela qu'il faut toujours faire de nombreux tests, avec intervention humaine, avant de mettre en production une application qui utilise l'IA.
Evidemment, les RAGs réels ne se limitent pas à consulter un seul fichier. Vous verrez dans le cours sur le RAG que les embeddings créés à partir de multiples fichiers ou bases de données de l'entreprise, de types divers (texte, pdf, docx, image pour certains LLMs,...), peuvent être enregistrés dans une base de données vectorielle persistante (pas un entrepôt conservé dans la mémoire, comme pour cet exemple). Ensuite, les informations les plus pertinentes pour répondre à une question sont retrouvées dans la base de données et sont utilisées pour répondre à la question.
Variante pour avoir une conversation avec l'assistant
A chaque nouvelle question posée à l'assistant vous devez recompiler le programme.
Voici du code qui va vous permettre de poser plusieurs questions à l'assistant dans une même session. Utilisez-la.
Test 5 : utilisation d'un outil
Vous venez de voir comment récupérer des informations depuis des fichiers privés.
Il est aussi possible d'utiliser des outils qui vont étendre les fonctionnalités d'un LLM. Un outil pourra, par exemple, faire des calculs mathématiques complexes, manipuler des bases de données, accéder au Web, gérer des emails. Les outils sont importants ; ils sont en particulier utilisés pour écrire des agents IA qui peuvent effectuer des tâches complexes. Les versions récentes des chatbots qui utilisent les LLMs (comme les applications ChatGPT, Gemini ou Claude Desktop) intègrent déjà des outils de base et certains permettent d'ajouter facilement d'autres outils.
Pour ce test, vous allez permettre au LLM d'utiliser un outil qu'il va pouvoir utiliser pour connaitre le temps qu'il fait dans une ville, au moment où le LLM répond à une requête. De base, un LLM n'a pas de connaissances en temps réel. Son savoir se limite aux informations présentes dans les données utilisées lors de son entrainement.
Vous allez utiliser pour cela l'API dont le endpoint de base est https://wttr.in/. Pour la tester, tapez cet URL dans votre navigateur : https://wttr.in/Paris
Essayez aussi cet URL : https://wttr.in/Paris?format=3 ; vous pouvez aussi tester d'autres numéros de formats.
Le cours vous explique comment mettre un outil à la disposition d'un LLM en utilisant LangChain4J. Voici une classe MeteoTool qui fournit wttr.in comme outil. Le paramètre de @Tools doit être assez clair pour que le LLM sache s'il a besoin de l'outil pour répondre à une requête.
Il vous reste à
- Ecrire le code de l'assistant IA. C'est une simple interface Java que vous appelerez
AgentMeteo(par exemple) ; aidez-vous du cours sur AiServices et du code du test 4 (c'est le même type de code que l'interfaceAssistant). - Ecrire le code de la classe principale (avec la méthode main) qui crée un
ChatLanguageModel, puis un assistant (de typeAgentMeteo) et finalement demande le temps qu'il fait à Paris (ou la ville de votre choix). Pour créer l'assistant, il faut indiquer que le LLM peut utiliser l'outil s'il le souhaite :AgentMeteo assistant = AiServices.builder(AgentMeteo.class) .chatLanguageModel(model) .tools(new MeteoTool()) // Ajout de l'outil .build();
Pour tester, demandez au LLM le temps de plusieurs villes et aussi donnez le nom d'une ville qui n'existe pas. Envoyez aussi au LLM une requête qui n'a rien à voir avec le temps pour voir comment il réagit.
Application Web
Revenons maintenant à l'application Web.
Création de l'application
Créez une nouvelle application Web avec Maven, un nouveau repository GitHub.
Page JSF
Vous connaissez déjà l'interface utilisateur. C'est celle du TP 1, sans le mode debug.
Créez la page JSF.
Code de la page JSF. Code fichier mycsslayout.css et script.js, à placer au bon endroit pour JSF, c'est-à-dire dans les répertoires webapp/resources/css et webapp/resources/js d'après le code de la page JSF (dans le header).
N'oubliez pas le commit Git et GitHub...
Backing bean
La portée du backing bean sera "view" afin de garder facilement les informations sur la conversation (c'est un chat...) entre l'utilisateur et l'API.
Le code est similaire au code du TP 1. La différence est que vous n'aurez pas à gérer le JSON et donc le backing bean va s'adresser directement au client de l'API du LLM.
Le backing bean injecte donc une instance de la classe LlmClient à laquelle il délègue l'interface avec l'API du LLM.
Git et GitHub...
Classe pour travailler avec les LLMs
La classe Java LlmClient est la classe "métier", celle qui est liée au LLM choisi (Gemini).
Rien de changé par rapport au TP 1 pour la clé de l'API du LLM.
Cette classe s'appuie sur LangChain4j. Aidez-vous du support de cours et des tests que vous avez écrits pour écrire le code de cette classe.
Voici quelques compléments pour vous aider.
Code de la classe LlmClient
Service IA
LangChain4j utilise la notion de "service IA" qui est une évolution de la notion de "chaîne" de LangChain, mieux adaptée au langage Java. Cette notion facilite l'écriture pour les cas plus complexes mais peut aussi être utlisée pour les cas simples.
Un service IA définit un comportement pour des échanges de messages entre l’application et le LLM.
Le développeur définit une interface Java qui contient les méthodes qui correspondent aux interactions que son application aura avec le LLM. Vous mettez dans cette interface les méthodes que vous voulez. LangChain4j fournira automatiquement une implémentation de cette interface avec un objet proxy (vous n'avez pas besoin d'implémenter l'interface). Les méthodes de l'interface seront des échanges de messages (questions et réponses) entre l’application et le LLM ; LangChain4j tient compte des types des paramètres, du type retour et des annotations des méthodes pour fournir les implémentations de l'interface Java.
Pour ce projet l'interface sera très simple, avec une seule interaction qu'on appelera chat (on peut choisir le nom que l'on veut) : une question (prompt) est envoyée au LLM et il répond :
public interface Assistant {
String chat(String prompt);
}
La classe AIServices de LangChain4j permet de créer une "instance de cette interface" (en fait c'est une instance de la classe "proxy" créée par LangChain4j, qui implémente l'interface). La classe LlmClient utilise cette instance pour envoyer des messages à l'API du LLM.
Variables d'instance de LlmClient
String systemRole: le rôle que l'utilisateur choisira pour l'assistant IA.Assistant assistant: Assistant est l'interface que vous avez défini pour décrire les interactions avec le LLM.ChatMemory chatMemory: la mémoire utilisée par l'assistant pour garder l'historique de la conversation. En effet, l'API des LLMs est sans état et c'est au client de garder l'état de la conversation (tous les messages échangés depuis le début de la conversation). Dans le TP 1 vous passiez l'historique à chaque requête. Maintenant, c'est LangChain4j qui va s'en occuper pour vous.ChatMemoryest une interface de LangChain4j qui facilite la gestion de l'état.
Constructeur de LlmClient
- Récupère la valeur de la clé secrète OpenAI avec la méthode Java standard
System.getenv. - Crée une instance de type
ChatLanguageModelqui représente le LLM. Pour la création du modèle, utilisez le builder pour passer la clé de l'API et donner le nom du modèle (gemini-1.5-flash). - Crée l'assistant en utilisant la classe AiServices fournie par LangChain4j. Remarquez la configuration de la mémoire pour garder jusqu'à 10 messages :
this.chatMemory = MessageWindowChatMemory.withMaxMessages(10); this.assistant = AiServices.builder(Assistant.class) .chatLanguageModel(model) .chatMemory(chatMemory) .build();
Méthodes de LlmClient
2 méthodes :
- Un setter pour le rôle système (celui indiqué par la liste déroulante de la page JSF). Il ajoute ce rôle à la mémoire, comme instance de type
SystemMessagepour qu'il soit pris en compte par le LLM. Lorsque le rôle système est mis, le contexte change tout à fait et donc il vaut mieux vider la mémoire avant de mettre le rôle système. - Une méthode qui envoie une requête au LLM et qui reçoit une réponse en retour. Cette méthode utilise l'instance de l'interface
Assistant(instance dont la classe est implémentée par LangChain4j comme c'est expliqué plus haut).
Test de l'application
Testez.
Git et GitHub si tout va bien.
Pour obtenir un autre bonus pour cette deuxième partie du TP, envoyez-moi un email avec l'URL du dépôt GitHub.
Correction
Page JSF (n'oubliez pas les fichiers JavaScript et CSS)
Backing bean
LlmClient.java
Assistant.java
Optionnel : Utilisation de LangChain4j et de WebSocket pour recevoir les réponses au fur et à mesure de leurs génération par le LLM
AVERTISSEMENT : Cet exercice est optionnel : vous n'êtes pas obligé de le faire. Remarque : le streaming avec Gemini est supporté à partir de la version 0.36.2 de LangChain4j.
Les LLMs affichent leurs réponses en streaming : ils n'attendent pas d'avoir généré tous les tokens de la réponse pour l'envoyer à l'utilisateur. Ils envoient les tokens de la réponse dès qu'ils les ont générés (en fait certains LLMs, comme Gemini, regroupent les tokens ; le streaming envoie alors des groupes de tokens et pas des tokens isolés). Vous allez faire de même.
Pour cela vous allez utiliser une option de LangChain4j qui permet d'obtenir la réponse token par token pour l'API du LLM.
Les échanges entre le serveur et la page JSF vont utiliser un websocket.Vous allez ajouter un websocket dans la page JSF de l'application qui fait l'interface avec l'utilisateur avec la balise <f:websocket>. Cette balise va indiquer les fonctions JavaScript qui seront exécutées lors d'événements liés au websocket.
Les questions de l'utilisateur sont envoyées à LlmClient, comme pour les versions sans streaming. Cette fois-ci, la méthode de LlmClient retourne un TokenStream.
Le backing bean configure le TokenBean (méthode onNext, onComplete, onError) et lance le processus d'envoi des tokens (start). La méthode onNext envoie le token reçu (en fait, plusieurs tokens sont souvent envoyés en une seule fois) dans le webSocket. La méthode onComplete envoie un événement particulier dans le webSocket pour déclencher l'exécution d'une fonction JavaScript qui va mettre à jour la conversation avec la réponse complète du LLM.
Pour les réponses courtes, il n'y aura pas un grand changement car les tokens sont envoyés à grande vitesse, mais si la réponse est longue, ou si le réseau est lent, vous verrez bien les tokens s'afficher au fur et à mesure.
Aide.
Tutoriel Jakarta EE sur WebSocket : https://jakarta.ee/learn/docs/jakartaee-tutorial/current/web/websocket/websocket.html et https://jakarta.ee/learn/docs/jakartaee-tutorial/current/web/faces-ws/faces-ws.html (pour utilisation avec JSF).
Correction
Page JSF
Backing bean Bb.java
Classe LlmClient.java
InterfaceAssistant.java
script.js